
Table of Contents
- Nested Loops
- Hash Join / Hash
- Why Did PostgreSQL Choose a Hash Join Instead of a Nested Loop?
- Merge Join
- Why Did PostgreSQL Choose a Merge Join Instead of Nested Loop or Hash Join?
- Summary
- References
- Next Steps
Nested Loops
Nested loops join is one of the simplest join strategies that PostgreSQL uses. It works by taking each row from one table (outer table) and finding matching rows in another table (inner table) by scanning or using an index.
How Nested Loops Join Works
When PostgreSQL performs a nested loops join:
- It first gets a row from the outer table (usually the table with fewer matching rows after filters)
- For each outer row, it scans the inner table (either sequentially or using an index) to find matching rows
- When matches are found, it combines the rows according to the join condition
- This process repeats for every row from the outer table
Nested loops are most efficient when:
- The outer table has very few rows after filtering
- The inner table has an index on the join columns
- The join needs to return only a small number of rows
think of this like a double for loop.
for (order in orders) { for (product in products) { if (order.product_id == product.id) { // join the order and product } }}
For example, in this query plan:
postgres=# explain select * from orders o join products p on p.id=o.product_id where o.id<107219; QUERY PLAN--------------------------------------------------------------------------------------- Nested Loop (cost=0.70..14.81 rows=11 width=50) -> Index Scan using orders_pkey on orders o (cost=0.42..2.62 rows=11 width=27) Index Cond: (id < 107219) -> Index Scan using products_pkey on products p (cost=0.27..1.11 rows=1 width=23) Index Cond: (id = o.product_id)(5 rows)Note: order is the outer table and product is the inner table.
Understanding the Query Plan
- The index scan on orders returns 11 rows.
- For each of these rows, the query performs an index scan on products.
- The index scan on products returns 1 row for each of the 11 orders.
Hash Join / Hash
Hash join is another join strategy that PostgreSQL uses. It works by creating a hash table from one of the tables and then using that hash table to find matching rows in another table.
How Hash Join Works
When PostgreSQL performs a hash join:
- It creates a hash table from one of the tables (usually the smaller one)
- It then uses that hash table to find matching rows in another table
- When matches are found, it combines the rows according to the join condition
Hash join is most efficient when:
- The join needs to return only a small number of rows
- The inner table has an index on the join columns
think of this like a hash map.
hash_map = {}for (product in products) { hash_map[product.id] = product}
for (order in orders) { if (hash_map[order.product_id]) { // join the order and product }}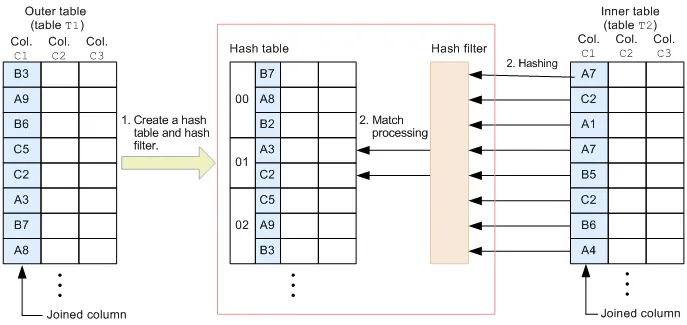
postgres=# explain select * from orders o join products p on p.id=o.product_id where o.id<117219; QUERY PLAN----------------------------------------------------------------------------------------- Hash Join (cost=15.68..339.95 rows=10536 width=50) Hash Cond: (o.product_id = p.id) -> Index Scan using orders_pkey on orders o (cost=0.42..296.81 rows=10536 width=27) Index Cond: (id < 117219) -> Hash (cost=9.00..9.00 rows=500 width=23) -> Seq Scan on products p (cost=0.00..9.00 rows=500 width=23)(6 rows)Note: orders is the outer table and products is the inner table.
Understanding the Query Plan
- The index scan on orders returns 10,536 rows.
- The hash join creates a hash table from the products table (smaller table).
- For each row in the orders table, the query uses the hash table to find matching rows in the products table.
- The hash join returns 10,536 rows.
Why Did PostgreSQL Choose a Hash Join Instead of a Nested Loop?
Key Differences from Previous Query (id < 107219):
- The previous query had only 11 rows from orders, so a Nested Loop Join was efficient.
- This query has 10,536 rows, so a Nested Loop would require 10,536 index lookups in products, which would be slow.
- Instead, PostgreSQL builds a hash table once (cheap) and does fast lookups
(O(1))instead of repeated index scans(O(log N)).
Merge Join
Merge join is another join strategy that PostgreSQL uses. It works by sorting the two tables and then merging them together.
How Merge Join Works
When PostgreSQL performs a merge join:
- It sorts the two tables by the join columns
- It then merges the two tables together
- When matches are found, it combines the rows according to the join condition
Merge join is most efficient when:
- Both tables are already sorted (or can be sorted efficiently).
- There’s no suitable index for a Nested Loop.
- The tables are large, making Hash Join expensive.
think of this like a merge sort.
merge_sort(left, right) { if (left.length == 0) return right; if (right.length == 0) return left;}
explainSELECT *FROM employees eJOIN salary s ON e.id = s.employee_idWHERE e.age < 40;
QUERY PLAN--------------------------------------------------------------Merge Join (cost=198.11..268.19 rows=10 width=488) Merge Cond: (e.id = s.employee_id) -> Index Scan using employees_id on employees e (cost=0.29..656.28 rows=101 width=244) Filter: (age < 40) -> Sort (cost=197.83..200.33 rows=1000 width=244) Sort Key: s.employee_id -> Seq Scan on salary s (cost=0.00..148.00 rows=1000 width=244)Understanding the Query Plan
- The index scan on employees returns 101 rows.
- The sort operation sorts the salary table by the join column (employee_id).
- The merge join then merges the two sorted tables together.
- The merge join returns 10 rows.
Why Did PostgreSQL Choose a Merge Join Instead of Nested Loop or Hash Join?
Key Differences from Previous Queries:
- The employees table is filtered (age < 40), reducing rows to 101.
- The salary table is not indexed on employee_id, so a Hash Join would require creating a large hash table.
- The tables can be efficiently sorted and merged, making a Merge Join the best option.
Summary
| Join Type | When It’s Used | How It Works |
|---|---|---|
| Nested Loop Join | Best for small outer tables (<1000 rows) or when inner table has indexes on join columns. Ideal when outer table is heavily filtered. | Iterates over each row of the outer table and checks for matches in the inner table using either sequential scan or index scan. Works like a double for-loop. |
| Hash Join | Optimal for medium to large tables with equality joins. Used when no useful indexes exist and memory is sufficient. | Builds an in-memory hash table from the smaller table, then probes it using rows from larger table. Hash table enables O(1) lookups. |
| Merge Join | Best when data is already sorted (e.g. clustered index) or when sort cost is acceptable. Good for large tables that exceed memory. | First sorts both inputs on join key if needed, then walks through them in parallel, matching rows. Similar to merge phase in merge sort. |
| Join Type | Time Complexity | Space Complexity |
|---|---|---|
| Nested Loop Join | O(n * m) without index, O(n * log m) with index where n=outer rows, m=inner rows | O(1) - Minimal memory usage |
| Hash Join | O(n + m) for building and probing | O(n) where n = size of smaller table |
| Merge Join | O(n log n + m log m) if sorting needed, O(n + m) if pre-sorted | O(1) if pre-sorted, O(n + m) if sorting needed |
References
Next Steps
- Apply all our learnings to a real query and optimize it.